
diymics.com
DIY microphone info you won’t find anywhere else
If you want detailed technical information on how to design and build a microphone, or want to know how microphones work beyond just the superficial level, you’ve come to the right place!
Why this blog is different
There’s already a lot of microphone info on the web, but this blog is different because it covers many microphone topics in much more detail than you’ll find anywhere else.
For example, suppose you’re curious about how shotgun microphones work. A quick web search will turn up many articles explaining that shotgun microphones use an interference tube to exploit the phenomenon of wave interference to suppress off-axis sound. But that’s as far as most explanations go. If you want to know more about the underlying physics, or how to predict a shotgun mic’s performance from its design parameters, you’ve been mostly out of luck…until now: check out my post on how shotgun microphones work for an example of the technical depth you’ll find here.
Or suppose you’re curious about the distance over which a parabolic microphone can pick-up voice. A quick internet search will turn up a variety of claims, ranging from tens to hundreds of feet…and usually with no accompanying rationale. So what’s the truth? What factors determine the reach of a parabolic mic, and how can it be estimated? You probably won’t find that information anywhere else but here: what’s the REAL maximum range of parabolic, shotgun, and other long-range directional microphones?
In general, I try not to post any information here that’s available in any other single place on the web. Most of what makes my content unique is its technical depth, but I also cover microphone subjects that are barely covered elsewhere, such as how horn microphones work.
Post categories
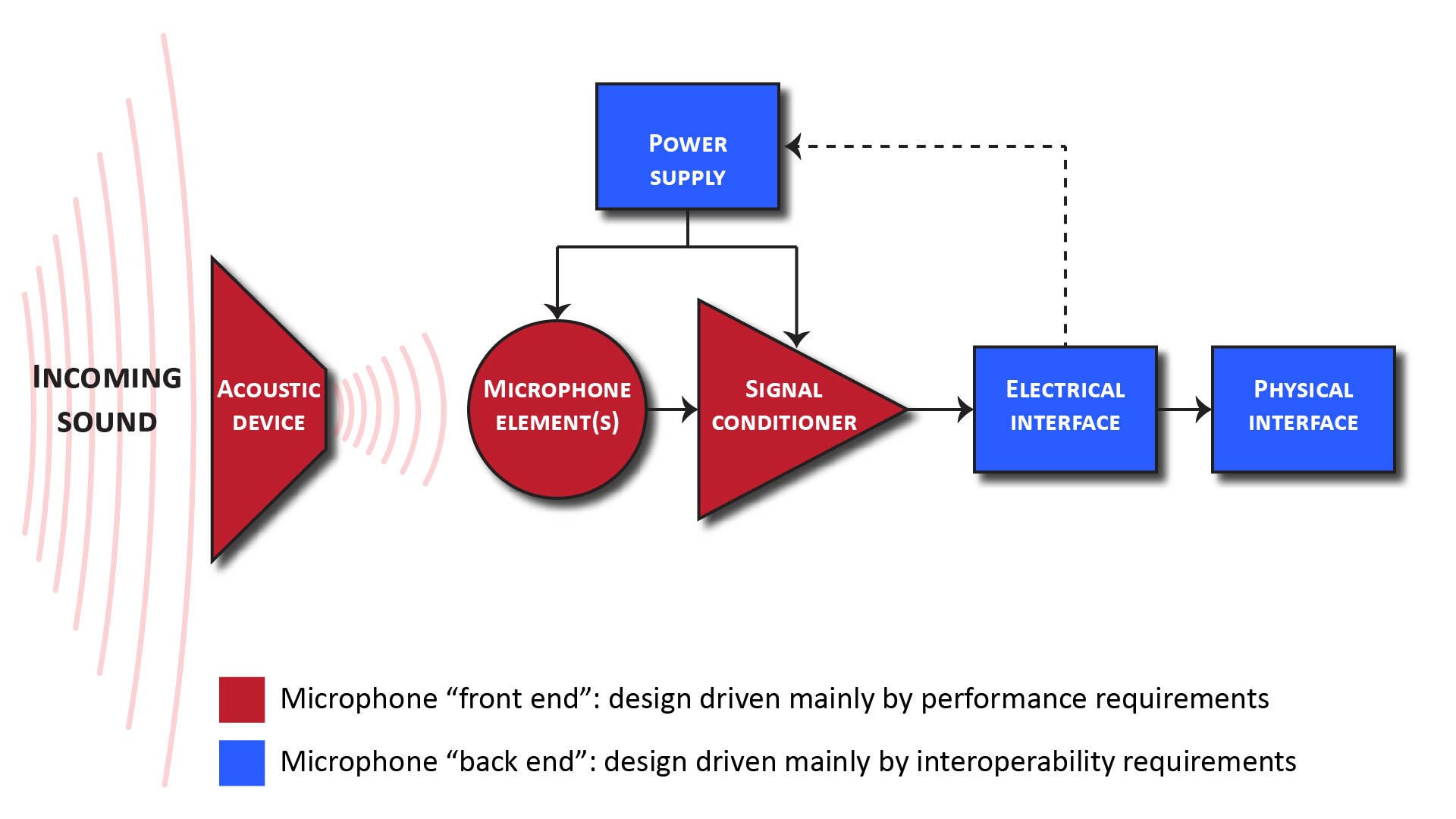


Studio microphones
Low-noise, bidirectional, cardioid, and boundary-layer microphones
Coming Soon

Wearable microphones
Lavalier, headset, and wireless microphones
Coming Soon
Microphone signal processing
Microphone equalization, filtering, and time-alignment
Coming Soon
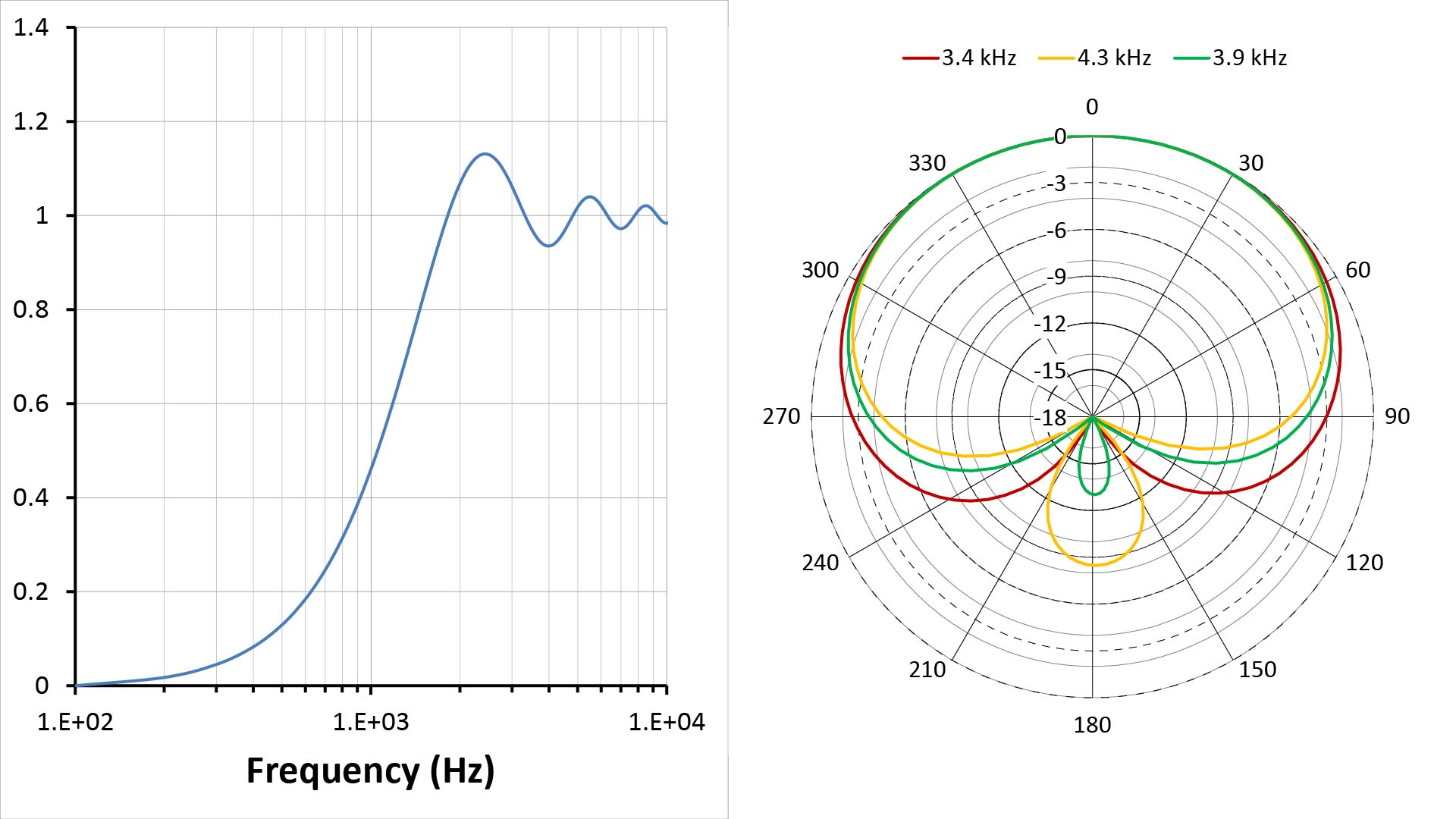
Microphone testing
Measuring frequency response, polar patterns, SNR
Coming Soon